Number(数字)
Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。math 模块提供了许多对浮点数的数学运算函数。cmath 模块包含了一些用于复数运算的函数。cmath 模块的函数跟 math 模块函数基本一致,区别是 cmath 模块运算的是复数,math 模块运算的是数学运算。- 要使用
math 或 cmath 函数必须先导入:
1
2
3
4
| import math
import cmath
|
Python数学常量
在math模块中定义了三个数学常量
1
2
3
4
5
6
|
e = 2.718281828459045
pi = 3.141592653589793
tau = 6.283185307179586
|
Python三角函数
要直接访问的,需要导入 math 模块, 然后通过 math 静态对象调用方法
| 函数 |
描述 |
| acos(x) |
返回x的反余弦弧度值。 |
| asin(x) |
返回x的反正弦弧度值。 |
| atan(x) |
返回x的反正切弧度值。 |
| atan2(y, x) |
返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) |
返回x的弧度的余弦值。 |
| hypot(x, y) |
返回欧几里德范数 sqrt(x*x + y*y)。 |
| sin(x) |
返回的x弧度的正弦值。 |
| tan(x) |
返回x弧度的正切值。 |
| degrees(x) |
将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) |
将角度转换为弧度 |
Python数学函数
| 函数 |
返回值 ( 描述 ) |
| abs(x) |
返回数字的绝对值,如abs(-12) 返回 12 |
| ceil(x) |
返回数字的上入整数(小数向上取整),如math.ceil(4.1) 返回 5, math.ceil(4.0) 返回 4 |
| cmp(x, y) |
如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1; (Python在3.x中已经弃用) |
| exp(x) |
返回e的x次幂, 如math.exp(2) 返回7.38905609893065 |
| fabs(x) |
返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) |
返回数字的下舍整数(小数向下取整),如math.floor(4.9)返回 4 |
| log(x) |
如math.log(math.e)返回1.0, math.log(100,10)返回2.0 |
| log10(x) |
返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) |
返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) |
返回给定参数的最小值,参数可以为序列。 |
| modf(x) |
返回x的整数部分与小数部分(元组形式),两部分的数值符号与x相同,整数部分以浮点型表示; 如:math.modf(99.09), 返回(0.09000000000000341, 99.0) |
| pow(x, y) |
x**y 运算后的值。 |
| round(x [,n]) |
返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数; 如round(90.09, 1)输出:90.1; 如:round(90.09)输出:90 |
| sqrt(x) |
返回数字x的平方根, 如:math.sqrt(4)返回 2.0 |
- 其中
abs() 和 fabs() 区别
abs()是一个内置函数,而fabs()在math模块中定义的。fabs()函数只适用于float和integer类型,而 abs() 也适用于复数
Python随机数函数
- 随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
- 随机数函数需要导入
random 模块,然后通过 random 静态对象调用函数方法
Python包含以下常用随机数函数:
choice
从序列(元组, 列表, 字符串)的元素中随机挑选一个元素
1
2
3
4
5
6
7
8
9
10
| import random
random.choice( seq )
print(random.choice((1, 3, 5, 2)))
print(random.choice([1, 2, 3, 4]))
print(random.choice("titanjun"))
|
randrange
返回指定递增基数集合中的一个随机数,默认基数缺省值为1, 默认类型为int
1
| randrange(self, start, stop=None, step=1, _int=int)
|
- 参数
start – 指定范围内的开始值,包含在范围内。stop – 指定范围内的结束值,不包含在范围内。step – 指定递增基数
1
2
|
print(random.randrange(100, 1000, 2))
|
random
随机生成的一个实数,它在[0,1)范围内
seed
该函数没有返回值, 改变随机数生成器的种子, 可生成同一个随机数
1
2
3
4
| random.seed(5)
print(random.random())
random.seed()
print(random.random())
|
shuffle
- 将列表的所有元素随机排序, 没有返回值
- 因元组不支持二次赋值, 所以元组不支持重新排列
1
2
3
4
|
list1 = [1, 2, 3, 4]
random.shuffle(list1)
print(list1)
|
- 随机生成一个在[x, y)范围内的实数
- 参数:
- x – 随机数的最小值,包含该值。
- y – 随机数的最大值,不包含该值。
1
| print(random.uniform(2, 5))
|
字符串
上一篇文章Python数据类型详解01介绍了字符串的一些基础知识, 这里就主要介绍字符创中常用的函数和语法
in 和 not in
判断字符串是否包含指定字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
str = 'Hello Python'
if ('llo' in str):
str += ' True'
else:
str += ' False'
print(str)
if ('py' not in str):
str += ' not in'
else:
str += ' in'
print(str)
// 分别输出
Hello Python True
Hello Python True not in
|
字符串格式化
把其他类型的数据格式化为字符串形式返回, 字符串和其他类型之间要有%分开
| 符号 |
描述 |
%c |
格式化字符及其ASCII码 |
%s |
格式化字符串 |
%d |
格式化整数 |
%u |
格式化无符号整型 |
%o |
格式化无符号八进制数 |
%x |
格式化无符号十六进制数 |
%X |
格式化无符号十六进制数(大写) |
%f |
格式化浮点数字,可指定小数点后的精度 |
%e |
用科学计数法格式化浮点数 |
%E |
作用同%e,用科学计数法格式化浮点数 |
%g |
%f和%e的简写 |
%G |
%f 和 %E 的简写 |
%p |
用十六进制数格式化变量的地址 |
使用方式
1
2
3
4
| print('che is %d' % 19)
// 跟C语言的写法
prin他("che is %d", 19)
|
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。format 函数可以接受不限个参数,位置可以不按顺序。
简单使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
str1 = '{} {}'.format('hello', 'python')
print(str1)
str2 = '{0}{1}'.format('Python', '字符串')
print(str2)
str3 = '{1} {0} {1}'.format('hello', 'che')
print(str3)
print("姓名: {name}, 年龄: {age}".format(name='che', age=18))
dic = {'name': 'jun', 'age': 20}
print("姓名: {name}, 年龄: {age}".format(**dic))
list0 = ['titan', 20]
print("姓名: {0[0]}, 年龄: {0[1]}".format(list0))
/*输出结果
hello python
Python字符串
che hello che
姓名: che, 年龄: 18
姓名: jun, 年龄: 20
姓名: titan, 年龄: 20
*/
|
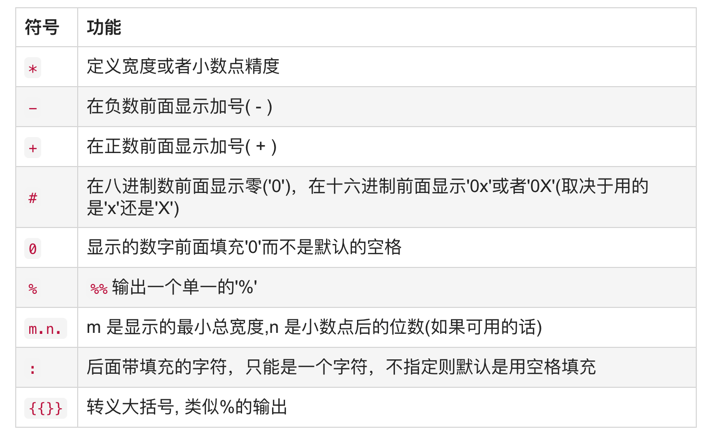
格式化操作符辅助指令
相关操作符具体的使用后面再说
![image description]()
数字格式化操作符
| 数字 |
格式 |
输出 |
描述 |
| 3.1415926 |
{:.2f} |
3.14 |
保留小数点后两位 |
| 3.1415926 |
{:+.2f} |
+3.14 |
带符号保留小数点后两位 |
| -1 |
{:+.2f} |
-1.00 |
带符号保留小数点后两位 |
| 2.71828 |
{:.0f} |
3 |
不带小数 |
| 5 |
{:0>2d} |
05 |
数字补零 (填充左边, 宽度为2) |
| 5 |
{:x<4d} |
5xxx |
数字补x (填充右边, 宽度为4) |
| 10 |
{:x<4d} |
10xx |
数字补x (填充右边, 宽度为4) |
| 1000000 |
{:,} |
1,000,000 |
以逗号分隔的数字格式 |
| 0.25 |
{:.2%} |
25.00% |
百分比格式 |
| 1000000000 |
{:.2e} |
1.00e+09 |
指数记法 |
| 13 |
{:10d} |
13 |
右对齐 (默认, 宽度为10) |
| 13 |
{:<10d} |
13 |
左对齐 (宽度为10) |
| 13 |
{:^10d} |
13 |
中间对齐 (宽度为10) |
进制转换(以十进制数字11为例)
| 进制 |
格式 |
输出 |
| 二进制 |
'{:b}'.format(11) |
1011 |
| 十进制 |
'{:d}'.format(11) |
11 |
| 八进制 |
'{:o}'.format(11) |
13 |
| 十六进制 |
'{:x}'.format(11) |
b |
| 小写十六进制 |
'{:#x}'.format(11) |
0xb |
| 大写十六进制 |
'{:#X}'.format(11) |
0XB |
1
2
3
4
5
6
7
8
9
10
11
| print('百分比: %d%%' % 23)
print('{}索引值: {{0}}'.format('jun'))
print('{:#x}'.format(9))
print('{:#X}'.format(9))
/*输出结果:
百分比: 23%
jun索引值: {0}
0x9
0X9
*/
|
字符串的内建函数
下列方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的
| 方法 |
返回结果 |
描述 |
'titan'.capitalize() |
Titan |
把字符串的第一个字符大写 |
'hello\tpython'.expandtabs() |
hello python |
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 |
str5.find('irl') |
11 |
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
str5.rfind('irl') |
11 |
同find方法, 从右向左查询 |
| str5.index(‘gi’) |
10 |
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| str5.rindex(‘gi’) |
10 |
同index方法, 从右向左查询 |
'jun0929'.isalnum() |
True |
至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
'titan'.isalpha() |
True |
至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
u'23e'.isdecimal() |
False |
字符串只包含十进制字符返回True,否则返回False(只针对unicode对象) |
"123456".isdigit() |
True |
字符串只包含数字则返回 True 否则返回 False |
'23e'.islower() |
True |
字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
u"23443434"isnumeric() |
True |
字符串中只包含数字字符,则返回 True,否则返回 False(只针对unicode对象) |
" ".isspace() |
True |
字符串中只包含空格,则返回 True,否则返回 False. |
'JING'.isupper() |
True |
字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
'-'.join( ['a', 's', 'd'] ) |
a-s-d |
用于将序列中的元素以指定的字符连接生成一个新的字符串 |
'THIS'.lower |
this |
返回将字符串中所有大写字符转换为小写后生成的字符串 |
"88this".lstrip('8') |
this |
返回截掉字符串左边的空格或指定字符后生成的新字符串 |
'this88'.rstrip('8') |
this |
返回截掉字符串右边的空格或指定字符后生成的新字符串 |
max('python') |
z |
返回字符串中最大的字母 |
min('python') |
h |
返回字符串中最小的字母 |
'https://www.titanjun.top'.partition('://') |
(‘https’, ‘://‘, ‘www.titanjun.top') |
返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串 |
'this'.startswith('th', 1, 4) |
False |
检查字符串在制定范围内是否是以指定子字符串开头 |
"0jun0".strip('0') |
jun |
返回移除字符串头尾指定的字符生成的新字符串 |
'Python'.swapcase() |
pYTHON |
返回大小写字母转换后生成的新字符串 |
'hello python'.title() |
Hello Python |
返回所有单词都是以大写开始 |
'jun'.upper() |
JUN |
返回小写字母转为大写字母的字符串 |
除了以上方法外还有下列重要方法
count()方法
返回子字符串在字符串中出现的次数
1
2
3
4
5
6
7
8
9
| str.count(sub, start= 0,end=len(string))
//使用
print('hello world'.count('l', 1, 8))
print('hello world'.count('l'))
//输出:
2
3
|
- 参数
sub – 搜索的子字符串start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
center()方法
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格
1
2
3
4
5
6
7
8
9
| str.center(width, fillchar)
//使用
>>> str = 'titan'
>>> str.center(8, '-')
'--titan---'
>>> str.center(9)
' titan '
>>>
|
- 不提供
fillchar 参数则默认为空格
- 当
width 参数小于等于原字符串的长度时,原样返回
- 无法使左右字符数相等时候,左侧字符会比右侧少 1
encode()方法
以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案
1
2
3
4
5
6
| str.encode(encoding='UTF-8',errors='strict')
//示例
'titan'.encode('UTF-8','strict')
//输出: b'titan'
|
encoding – 要使用的编码,如”UTF-8”。errors – 设置不同错误的处理方案。默认为 strict,意为编码错误引起一个UnicodeError。 其他可能得值有 ignore, replace, xmlcharrefreplace, backslashreplace 以及通过 codecs.register_error() 注册的任何值。
endswith()方法
用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False
1
2
3
4
5
6
7
8
| str.endswith(suffix[, start[, end]])
//使用示例
str5 = 'her is my girl friend haha!!'
print(str5.endswith('!!'))
print(str5.endswith('ha', 0, len(str5) - 2))
//输出结果: 都是True
|
suffix – 该参数可以是一个字符串或者是一个元素start – 字符串中的开始位置, 可不传end – 字符中结束位置, 可不传
ljust() 和 rjust()方法
ljust(): 返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串rjust(): 返回一个原字符串右对齐- 参数
width – 指定字符串长度。fillchar – 填充字符,默认为空格
1
2
3
4
5
6
7
8
9
10
11
| str.ljust(width[, fillchar])
str.rjust(width[, fillchar])
//测试用例
str = "this is string example....wow!!!";
print str.ljust(50, '0');
print str.rjust(50, '0');
//输出:
this is string example....wow!!!000000000000000000
000000000000000000this is string example....wow!!!
|
replace()方法
返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次
1
2
3
4
5
6
7
8
| str.replace(old, new[, max])
//测试
str = 'Python is a good language!'
print(str7.replace('o', 'i', 2))
//输出:
Pythin is a giod language!
|
split()方法
通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则仅分隔 num 个子字符串
1
2
3
4
5
6
7
8
9
10
| str.split(str="", num=string.count(str))
//测试
str7 = 'Python is a good language!'
print(str7.split(' '))
print(str7.split(' ', 3))
//输出:
['Python', 'is', 'a', 'good', 'language!']
['Python', 'is', 'a', 'good language!']
|
splitlines()方法
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符
1
2
3
4
5
6
7
8
9
10
11
12
| str.splitlines([keepends])
//测试
str8 = 'ab c\n\nde fg\rkl\r\n'
print(str8.splitlines())
str9 = 'ab c\n\nde fg\rkl\r\n'
print(str9.splitlines(True))
//输出:
['ab c', '', 'de fg', 'kl']
['ab c\n', '\n', 'de fg\r', 'kl\r\n']
|
- 对于
Python语言, 我也正在努力学习中, 文中如有不足之处, 还望多多指教
- 测试代码详见 GitHub地址
- 后期会持续更新相关文章, 未完待续…